RAG vs Fine-Tuning for Customer Support: Which One Your Bot Actually Needs
For most customer support bots, RAG is the right default and fine-tuning is the exception. Here is how to tell which one you need, what each costs to run, and where a hybrid makes sense.
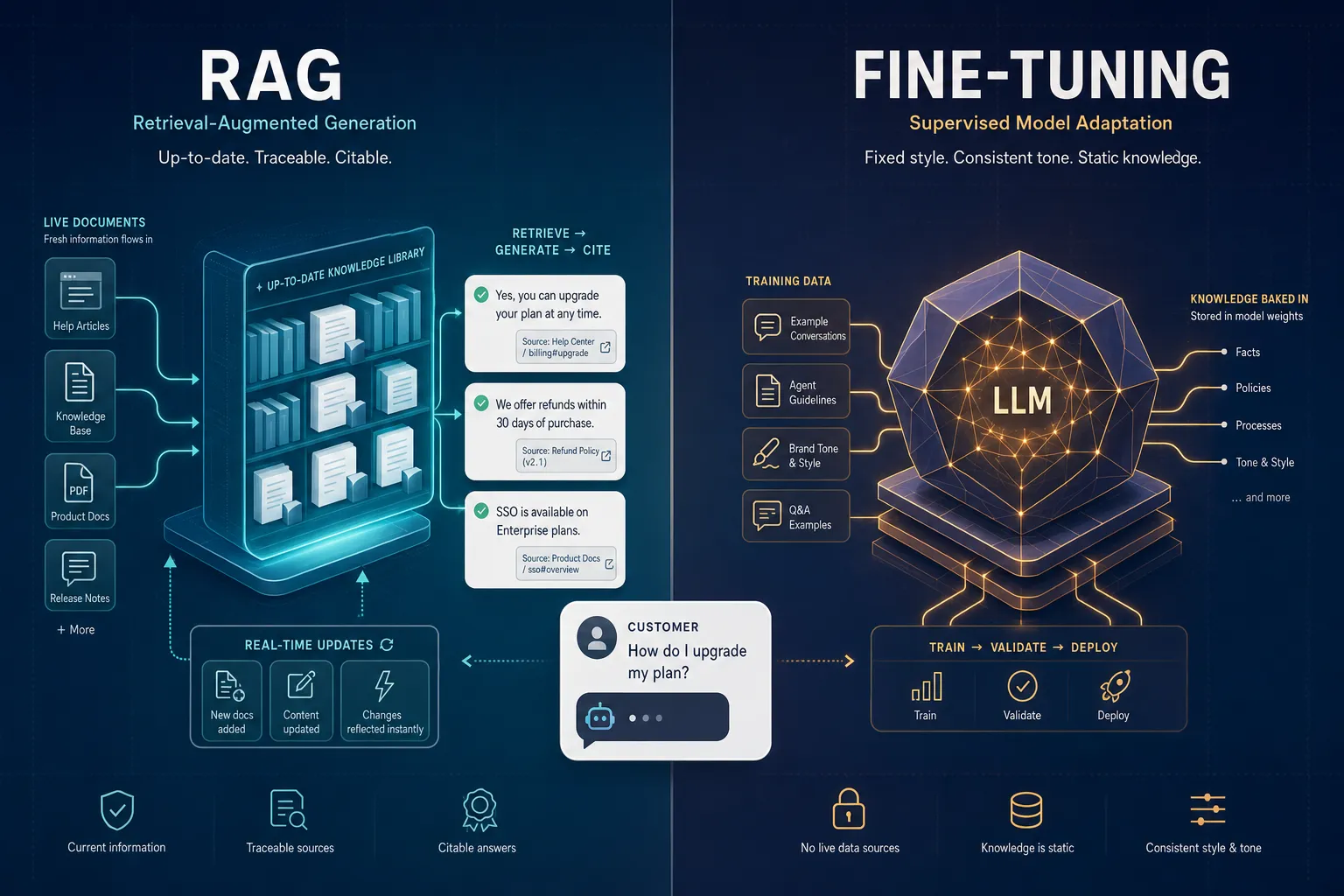
If you are building an AI agent for customer support, you will hit one fork early: should you use RAG (retrieval-augmented generation) or fine-tune a model on your data? For most support bots, the answer is RAG, and fine-tuning is the exception you reach for later, if at all.
The two approaches solve different problems, and a lot of the confusion comes from the word “training.” When a no-code tool says it “trains a chatbot on your website and PDFs,” it almost always means RAG, not fine-tuning. Knowing the difference saves you from paying for the wrong solution to a problem you do not have.
This guide is written for someone choosing an AI support tool or scoping a build, not for an ML team optimizing a research pipeline. Owlish is our product and it is RAG-based, so I will be upfront about where it fits and where it does not.
What the two approaches actually change
The cleanest way to keep them straight is to ask: what changes when your knowledge changes?
RAG leaves the model alone and changes the sources. Your help docs, PDFs, and policies are stored in a searchable index. When a customer asks a question, the system retrieves the most relevant chunks and passes them into the model’s context so the answer is built from your current content. Red Hat describes it as supplementing the model “by retrieving information from sources of your choosing.” Red Hat
Fine-tuning leaves the sources alone and changes the model. You take a pretrained model and train it further on a smaller, targeted dataset so it absorbs patterns, tone, or domain language into its weights. Red Hat calls it “training a pretrained model further with a smaller, more targeted data set.” The knowledge becomes part of the model rather than something it looks up.
That single distinction drives almost every practical tradeoff below.
Why RAG is the right default for support
Customer support is mostly a knowledge problem. Customers ask about pricing, shipping, refunds, setup, account rules, and policy edge cases. The answers live in content you already maintain, and that content changes. RAG fits this shape for four reasons.
Your answers stay current. Update a help page or re-sync a PDF, and the next answer reflects it. There is no retraining step. Red Hat notes RAG “pulls the most up-to-date data,” while a fine-tuned model’s information “can become outdated and require retraining.” For pricing and policy, that freshness is the whole game.
You can cite sources. Because the answer is built from retrieved chunks, the system can show which source it used. Citations are what make an AI answer auditable: the customer can verify it, and your team can fix the source behind a bad reply instead of guessing what the model did. Fine-tuning gives you no such trail; the knowledge is dissolved into weights.
It is cheaper to run and change. RAG is generally considered more cost-efficient than fine-tuning because you are not paying for repeated training runs or labeled datasets. Adding a new answer means adding a document, not launching a job.
It can refuse. When retrieval finds nothing relevant, a well-built agent can say it does not know and hand off to a human, rather than inventing an answer. A fine-tuned model that has “learned” your domain is more likely to produce a confident, wrong answer for a question your content never covered.
Chatbase, an AI support chatbot vendor, makes the same call for support use cases: RAG suits “frequently changing, personalized, or real-time data,” which is most of what a support agent handles. Chatbase
What fine-tuning is actually good at
Fine-tuning is not useless for support. It is just aimed at a narrower target: how the model behaves, not what it knows.
Fine-tuning earns its cost when you need:
- A consistent voice and format at scale. If you want every reply to follow a precise structure, register, or brand tone that prompting cannot hold reliably, fine-tuning can bake that in.
- Dense domain language. Industries with heavy jargon, acronyms, or classification tasks (routing, sentiment, intent tagging) can benefit from a model tuned on labeled examples.
- Latency or cost at very high volume. A smaller fine-tuned model can sometimes match a larger general model on a narrow task more cheaply, once you are running enough volume to amortize the training.
Notice what is missing from that list: facts. Fine-tuning is the wrong tool for “teach the bot our refund policy,” because policies change and the model would need retraining every time. It is good at style and skill, weak at fresh knowledge.
A quick way to decide
The choice usually comes down to whether your problem is about knowledge or behavior. Use this:
| If your main need is… | Reach for… |
|---|---|
| Answering questions from docs, FAQs, policies that change | RAG |
| Showing customers where an answer came from | RAG |
| Updating answers without an engineering cycle | RAG |
| A locked, consistent tone or output format at scale | Fine-tuning |
| Heavy domain jargon, intent/sentiment classification | Fine-tuning |
| Both fresh facts and a strict house style | Hybrid (RAG + light fine-tuning) |
If you scan that and almost everything you need lands in the RAG row, that is your answer. Most support teams never leave it.
The hybrid pattern, and when it is worth it
The two approaches are not mutually exclusive. Red Hat notes you can “customize a model by using both fine-tuning and RAG architecture.” The common production pattern is to fine-tune for style (tone, format, reasoning habits) and use RAG for facts (the live knowledge base).
It is a real pattern, but it is also more moving parts: a training pipeline to maintain, eval sets to keep honest, and a retrieval system on top. For a small or growing support team, the cost rarely pays off before you have a high volume and a strong reason that prompting plus RAG could not solve. Reach for hybrid when you have proven RAG works and the only remaining gap is a behavioral one that instructions cannot close. Do not start there.
The mistake that wastes the most money
The single most common error is reaching for fine-tuning to “teach the AI our product and policies.” It feels like the serious, thorough option. It is usually the wrong one.
Fine-tuning a model on your policy docs gives you a model that has memorized a snapshot of those docs, with no citation trail and no easy way to update when the policy changes next month. You will have spent on a training run to get a worse version of what RAG gives you for the cost of an upload. If the goal is “the bot should know our current answers,” that is a retrieval problem, not a training problem.
The honest version of “we trained our bot on our data” is almost always: we indexed our content for retrieval, wrote clear sources, and tested the answers. That is RAG.
How to tell which one you need
Run your situation through these questions before you commit:
- Does the right answer change? If pricing, stock, policy, or product details shift, you need retrieval, not retraining.
- Do you need to show your work? If customers or operators must verify answers, you need citations, which means RAG.
- Is the problem knowledge or behavior? Wrong facts point to RAG. Wrong tone or format points to fine-tuning.
- Have you exhausted prompting? A clear system prompt and good source content close most “behavior” gaps without any fine-tuning.
- Do you have the volume to amortize training? If you are not running heavy, repeated volume on a narrow task, fine-tuning’s cost rarely returns.
If you answered “knowledge,” “yes I need citations,” and “I have not really pushed prompting yet,” you do not need fine-tuning. You need a clean knowledge base and good retrieval.
Where Owlish fits
Owlish is built on the RAG side of this split on purpose. You connect sources, the agent retrieves from them, and answers come back grounded with citations. You shape tone and refusals with instructions, not by retraining a model.
In practice that means:
- You bring sources, not training data. Owlish ingests websites for help centers and docs, files like PDF, DOCX, CSV, TXT, Markdown, and HTML, and short Direct Response entries for canonical answers. Websites can re-sync on a schedule so answers stay current. Files support OCR fallback for scanned PDFs.
- Answers can cite their source. Owlish renders citation chips so a customer or operator can inspect what an answer was built from. That is the QA surface fine-tuning cannot give you.
- Tone is configuration, not training. You set voice and fallback behavior in the agent settings, which covers most of what teams imagine they need fine-tuning for.
- It hands off when it should. When the answer is not in your sources or the question needs judgment, the agent can route to a human instead of guessing.
Owlish is a good fit if you want no-code setup from your existing content, source-cited answers in a web widget or team chat, and a fast path from a support gap to a new answer. Starter is $49/mo monthly or $39/mo billed annually (save ~20%), and there is a free tier to test the workflow.
Owlish is not the right tool if your core need is genuine model fine-tuning: a custom-trained model for a specialized classification task, a tightly controlled in-house RAG stack on your own infrastructure, or a large enterprise contact-center suite with deep telephony routing. If you truly need fine-tuning, you want an ML platform and a team to maintain it, not a no-code support tool. Be honest with yourself about which problem you have first.
FAQ
Do I have to fine-tune a model to train a chatbot on my own data?
No. In almost every no-code support tool, “training on your data” means RAG: your content is indexed and retrieved at answer time. You are giving the model better sources to read, not changing its weights. Fine-tuning is a separate, heavier process most support teams never need.
Is RAG or fine-tuning cheaper for customer support?
RAG is generally cheaper to run and to change, because there is no repeated training run or labeled dataset, and updating an answer is just updating a document. Fine-tuning carries data-prep and compute costs up front and again every time the knowledge changes, which is often in support.
Does RAG stop hallucinations?
It reduces them by grounding answers in retrieved sources and enabling citations, but it does not eliminate them. The agent can still answer poorly if your sources are vague, contradictory, or missing. Good source writing plus a refusal-and-handoff path is what makes grounding reliable.
Can I use both RAG and fine-tuning together?
Yes. A common production pattern is fine-tuning for tone and format and RAG for live facts. It works, but it adds a training pipeline and evaluation overhead, so it is usually worth it only after RAG is proven and the only remaining gap is behavioral.
Does Owlish fine-tune a model on my content?
No. Owlish uses retrieval with grounded citations and lets you control tone and fallbacks through instructions. That covers the knowledge and behavior needs of most support teams without the cost and staleness of fine-tuning. If you specifically need a fine-tuned model, a dedicated ML platform is the better fit.
Start with the simpler tool
RAG is the default for customer support because support is a knowledge problem with content that changes and answers that need to be verifiable. Fine-tuning is a real tool, but it is for behavior, not facts, and it is rarely the first thing a support team should buy.
If you want to try the RAG workflow without a training pipeline, start small in Owlish: connect one help-center URL, add a few Direct Response answers for your highest-volume questions, turn on citations, and test the top questions before you widen the rollout. Build your first agent walks through it.
Company and product names mentioned here are trademarks of their respective owners. Owlish is not affiliated with or endorsed by them unless explicitly stated. Cited claims reflect publicly available sources as of June 2026; verify current details against each source’s official documentation.