What Is a Good Ticket Deflection Rate? A Realistic 2026 Benchmark
A good ticket deflection rate is the one you can defend. This guide explains how deflection is calculated, why it is not the same as resolution, what a realistic benchmark looks like in 2026, and how to raise it without faking the number.
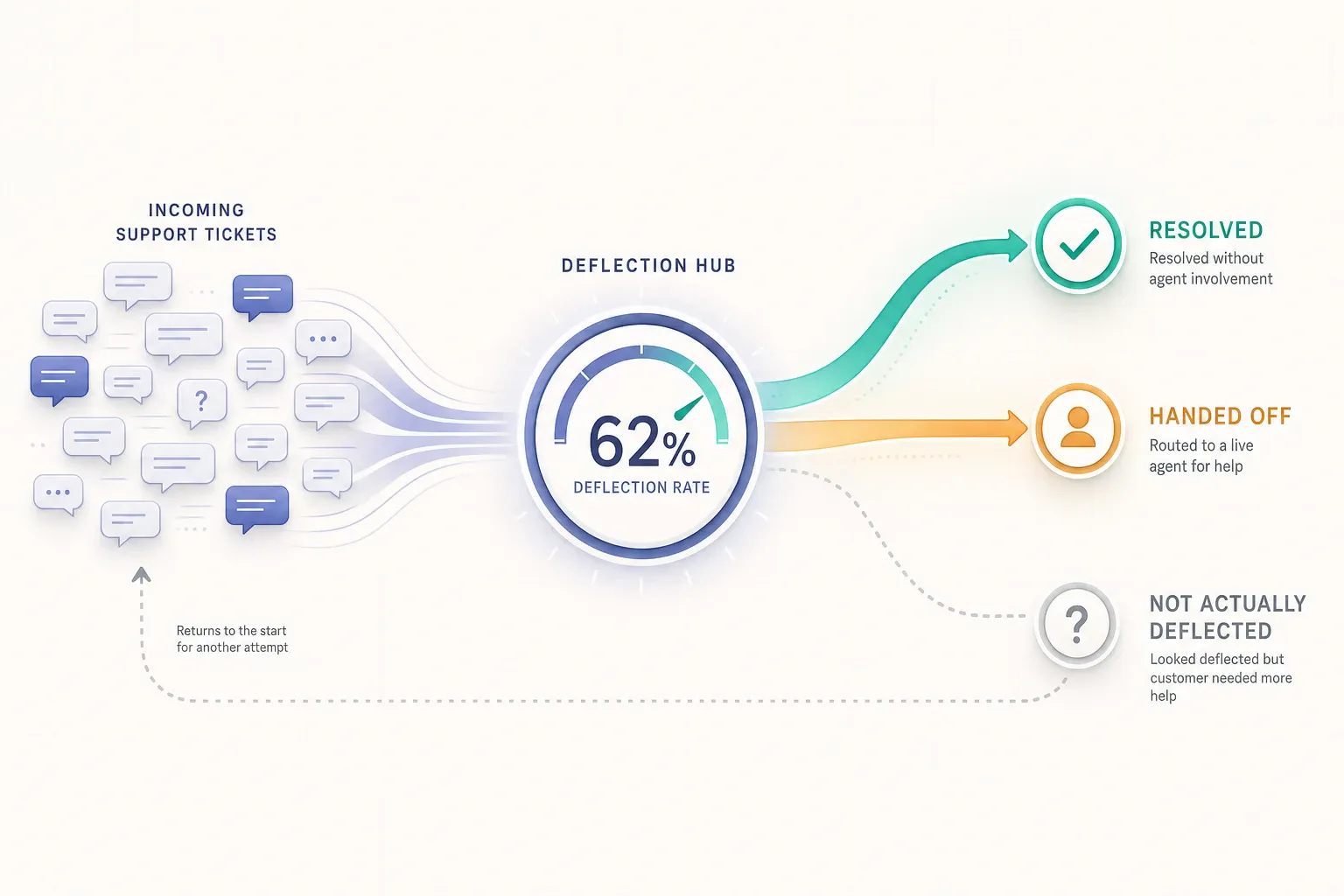
A good ticket deflection rate is not a number you copy from a vendor slide. It is the share of tickets your AI kept out of the queue and actually resolved, which is usually lower than the figure on the slide.
Most teams ask “what deflection rate should we hit?” before they ask “what is this number even counting?” That order is backwards, and it leads to dashboards that look great while customers quietly come back a second time. This guide fixes the order: what deflection measures, why it drifts away from real resolution, what a defensible 2026 benchmark looks like, and the practical moves that raise it honestly.
Ticket deflection rate, defined
Ticket deflection rate is the percentage of support requests that get answered before they reach a human agent. The standard formula is simple:
Deflection rate = self-service resolutions ÷ total support interactions × 100
If 1,000 people start a support interaction in a month and 400 of them get their answer from an AI agent, a help article, or a guided flow without opening a ticket, your deflection rate is 40%.
The appeal is obvious. Every deflected ticket is one your team does not have to read, route, and reply to. At scale that is real money and real time back. The problem is hidden inside the word “resolutions” in that formula, because a lot of things get counted as a self-service resolution that were nothing of the sort.
Deflection is not resolution, and the gap matters
Deflection counts tickets that never reached a human. Resolution counts issues that were actually solved. Those are different events, and treating them as the same is the most common way deflection numbers lie.
A customer who asks a question, gets an irrelevant FAQ link, sighs, and gives up has been “deflected.” So has a customer whose chat session timed out, and a customer who closed the widget because the bot kept looping. None of them got help. All of them count toward a naive deflection rate, and some of them will be back tomorrow, angrier, in a channel you do not measure.
Here is the arithmetic that should worry you. Imagine a team reporting 60% deflection. If you go back and check which of those interactions ended with the customer’s problem genuinely solved, you might find only 25% clear that bar. The other 35 points are diversions, not solutions: abandons, timeouts, and “close enough” article links that the customer never actually used. The headline says you removed 60% of the work. Reality removed less than half of that.
| Metric | What it actually counts | The trap |
|---|---|---|
| Deflection rate | Tickets that never reached a human | A timeout, an abandon, or an ignored bot all count as “deflected” |
| Resolution rate | Issues the AI genuinely solved | Harder to inflate; it needs a confirmation signal |
| Repeat contact | The same customer coming back | The honest cross-check on both numbers |
The distinction is not academic. The industry has been quietly shifting the language because of it. Intercom prices its Fin agent on resolutions, at $0.99 each, not on deflections, and frames its customer results the same way. One Intercom case study quotes Lightspeed’s support leader saying Fin “successfully resolves up to 65% end-to-end.” (Fin by Intercom, Intercom pricing) Charging for a resolution rather than a deflection is a tell: the thing worth paying for is the solved problem, not the dodged ticket.
What counts as a “good” deflection rate in 2026
Honest answer first: published benchmarks are inconsistent, often self-reported, and rarely define their terms the same way, so treat any single percentage with suspicion. With that caveat, here is a realistic frame.
For deflection measured honestly, with a resolution check behind it, most teams land somewhere in the 30% to 50% band once their knowledge base is in good shape. Numbers materially above that are achievable, but they usually mean one of two things: either the content and routing are genuinely excellent, or the measurement is counting diversions as wins. When you see a vendor headline at 70% or 80%, the first question is not “how do I get there” but “how are they defining a resolution.”
Two forces set the realistic ceiling for your own number:
- Question mix. A product with a tight, well-documented set of repeat questions (shipping, returns, password resets, plan limits) can deflect a large share, because the same answers recur. A product with sprawling, account-specific, or judgment-heavy questions cannot, and should not try to.
- Honesty of the denominator. If you only count interactions that started in the bot, you will report a higher rate than a team that counts every support contact across email, chat, and channels. Same product, different math.
The expectation pressure is real, which is why this metric gets gamed. Zendesk’s CX Trends research has reported that a large majority of consumers now expect service to be available around the clock, and that they expect faster replies than a year ago. (Zendesk CX Trends) That demand is exactly why a team will reach for a deflection number that flatters the dashboard. Resist it. A defensible 38% beats a fictional 75% the first time a customer escalation lands on a founder’s desk.
How to calculate deflection without fooling yourself
The fix is to never report deflection on its own. Pair it with a resolution signal and a repeat-contact check, and the number stops lying.
- Fix the denominator before the numerator. Decide exactly which interactions count as “support requests.” If you measure deflection only inside the chat widget, say so, and do not present it as your whole-support number.
- Require a resolution signal, not just an exit. A deflection should only count when there is evidence the issue was handled: an explicit “this solved it,” a thumbs-up, a checkout that completed, or simply no follow-up contact from that customer within a defined window. An exit without a signal is unknown, not solved.
- Subtract the false deflections. Timeouts, abandons mid-answer, and sessions that ended right after the bot dodged with “I can’t help with that, try our help center” are not wins. Track them as a separate bucket so they cannot hide inside the headline.
- Watch repeat contact for AI-handled issues. If deflection is up but the same customers reappear within a week, you did not deflect the ticket. You delayed it and added a bad first impression. This single cross-check catches most inflated numbers.
If you want the full scorecard this fits into, our guide on AI customer service metrics walks through verified resolution rate, citation quality, and handoff timing as a connected set rather than one vanity number.
Five ways to raise deflection rate honestly
Raising the number the right way means solving more issues, not dodging more tickets. Five moves do most of the work.
1. Ground every answer in your real content
An agent that guesses from general training will deflect tickets and create new ones, because some of its confident answers are wrong. An agent that answers only from your ingested help content, product docs, and policies stays inside what you can stand behind. Grounding is the difference between deflection that holds and deflection that bounces back. Our write-up on why AI support agents fail covers the failure modes that ungrounded answers create.
2. Show the source so answers are verifiable
When an answer carries a citation to the help article or doc it came from, two things improve at once. Customers trust the reply enough to act on it, and your team can audit what the agent used. Verifiable answers get accepted more often, which raises genuine resolution, which is the only kind of deflection worth counting.
3. Write your docs for the questions people actually ask
Retrieval can only find what exists. Pull your top contact reasons, then make sure each one has a clear, current, answerable source. The fastest deflection gains usually come from writing five missing help articles, not from tuning the model. The AI knowledge base guide goes deep on structuring content so retrieval can find it.
4. Let the agent refuse and hand off instead of guessing
Counterintuitively, giving the agent permission to say “I’m not sure, let me get a person” raises trustworthy deflection. It removes the confident-wrong answers that generate repeat contacts, and it makes every answer the agent does give more credible. A clean human handoff that carries the conversation context is the safety valve that lets you deflect aggressively on the easy questions without risking the hard ones.
5. Close the loop on source gaps
When the agent cannot answer, that is a signal, not a dead end. Log the unanswered questions, group them, and feed the common ones back into your knowledge base. A deflection program that improves its own content every week compounds. One that ships once and never updates decays as your product changes.
When a high deflection rate is a red flag
A rising deflection rate is good news only if the supporting numbers move with it. Treat the following as warnings that you are gaming the metric rather than improving support:
- Deflection is up but CSAT is flat or falling.
- Repeat-contact rate for AI-handled topics is climbing.
- Escalations arrive with “I already tried the bot and it didn’t help.”
- Volume shifts to channels you do not measure (social, email, a second chat) right as your widget deflection improves.
Any one of these means the tickets did not disappear. They moved, or they are coming back. A deflection rate that goes up while customer effort goes up is not a success metric. It is a leak you have stopped looking at.
Where Owlish fits
Owlish is our product, so read this section as a vendor being specific rather than neutral.
Owlish is built around the honest version of deflection. The agent answers from the website, documents, and PDFs you ingest, so its replies stay inside content you control. (knowledge base overview) You can turn on source citations, so a deflected answer is one the customer and your team can both verify. When the agent should not answer alone, it hands the conversation to a human with the context attached rather than dead-ending the customer. (human handoff) You deploy it as a web widget on the pages where questions actually start.
That shape is good for small and growing teams that want to deflect the repeat questions safely and measure what they actually resolved. It is a weaker fit if you need a full ticketing suite with telephony, deep routing, and CRM-grade workflows. If that is your requirement, a larger service platform will serve you better, and you should pick one of those instead. Owlish is the AI support layer, not the whole contact center.
FAQ
What is a good ticket deflection rate?
There is no universal number. For honestly measured deflection, with a resolution check behind it, most teams land in the 30% to 50% range once their knowledge base is solid. Figures well above that are real for narrow, well-documented products and suspect for everyone else, because they often count diversions as resolutions.
Is deflection rate the same as resolution rate?
No. Deflection counts tickets that never reached a human. Resolution counts issues that were actually solved. A timeout or an ignored bot reply can inflate deflection while resolution stays low. Always report the two together.
How do I calculate ticket deflection rate?
Divide self-service resolutions by total support interactions and multiply by 100. The honest version requires a resolution signal (an explicit confirmation, a completed action, or no repeat contact in a set window) so that abandons and timeouts do not get counted as wins.
Can an AI agent deflect 80% of tickets?
Sometimes, for products with a tight, repetitive question set and excellent content. For most teams, a claim that high is a measurement artifact. Check how the vendor defines a resolution and whether repeat-contact rate is included before trusting it.
Does pushing deflection higher hurt CSAT?
It can, if you raise it by dodging tickets instead of solving them. Deflection that comes from grounded, cited answers and clean handoff tends to hold CSAT steady or improve it. Deflection that comes from timeouts and “try the help center” replies erodes it.
Sources
- Fin by Intercom — resolution-based positioning and customer results
- Intercom pricing — $0.99 per resolution
- Zendesk CX Trends — consumer expectation data on availability and response speed
Trademark note
Intercom, Fin, Zendesk, and other product names mentioned here are trademarks or registered trademarks of their respective owners. Owlish is not affiliated with or endorsed by those companies unless explicitly stated.
Where to start with Owlish
If you want deflection you can defend, start by grounding an agent in your real help content and turning on citations, then watch resolution and repeat-contact alongside the deflection number. Read the knowledge base overview, see the pricing page for plan details, then walk through building your first agent. You will know within a week whether the deflection is holding or just hiding the tickets.