AI Customer Service Agent POC: A Practical Test Plan
A practical AI customer service agent POC plan for testing real support questions, citations, handoff quality, and post-launch improvement.
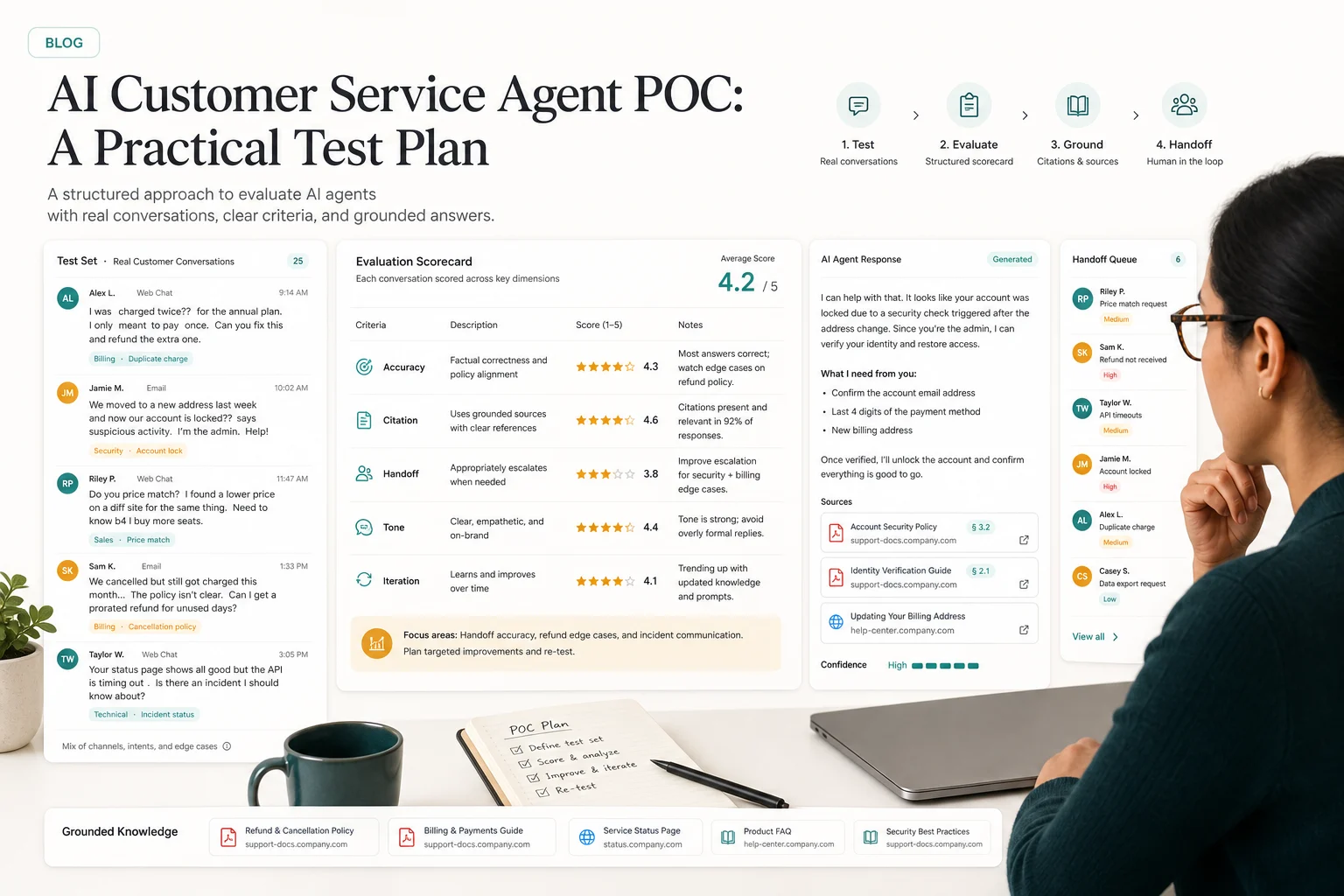
An AI customer service agent POC should prove more than answer accuracy. It should show that the agent can handle messy customer questions, cite the right source, stop at the right time, and improve after launch.
That matters because most failed AI support rollouts do not fail in the demo. They fail when the agent meets vague questions, missing policies, angry customers, duplicate docs, and handoffs that give humans no context.
This guide is for support leaders, founders, and operators evaluating an AI customer service agent, website chatbot, or AI helpdesk automation workflow. The first half is vendor-neutral. The second half explains where Owlish fits, because Owlish is our product.
A customer service AI POC is not a demo
A demo shows what an AI agent can do under friendly conditions.
A POC should show what happens under realistic conditions:
- the customer uses a typo or a half-written sentence
- the answer depends on two policies, not one article
- the public docs are missing a detail
- the customer asks for a human
- the question is emotional, private, or risky
- the agent should refuse instead of guessing
- the support lead needs to know exactly why an answer passed or failed
Intercom made the same point in a May 2026 post about evaluating AI agents for customer service: performance scores alone are not enough. Intercom recommends testing multi-turn queries, vague inputs, edge cases, sensitive scenarios, rephrased questions, multiple knowledge sources, and handoff behavior before deciding that an agent is production-ready. Intercom
That is the bar for a useful POC. Do not ask, “Did the model sound smart?” Ask, “Would we trust this answer in front of customers next week?”
Pick the support lane before you pick the tool
The first decision in an AI customer service agent POC is not the vendor.
It is the lane you are testing.
Answer lane
The agent answers customers directly when the request is common, low-risk, and backed by a current source.
Good POC examples:
- plan limits
- refund window basics
- setup instructions
- file type support
- shipping policy
- password reset steps
- web widget installation steps
These questions are good POC material because the answer can be checked against a source. If the agent cannot cite the answer, it does not pass.
Draft lane
The agent drafts a response for a human when the issue is documented but still needs judgment.
Good POC examples:
- a billing question that references an invoice
- a frustrated customer asking about an exception
- a technical issue with several possible causes
- a refund request where the policy is clear but the final decision is not
- a complaint where tone matters as much as the factual answer
Slack’s May 2026 Workflow Builder update is a useful example of this middle lane. Slack describes a customer support workflow where AI can summarize ticket history and suggest a response before an agent opens the case. That is real automation even though a human still owns the final reply. Slack
Handoff lane
The agent stops and hands off when the question is unsupported, sensitive, emotional, or unsafe to answer alone.
Good POC examples:
- refund exceptions
- account ownership disputes
- legal or compliance questions
- security incidents
- private account data
- angry complaints
- repeated clarification loops
- anything the knowledge base does not cover
Do not treat handoff as a POC failure. Late handoff is the failure. Clean handoff is part of a good support system.
Build the POC test set from real conversations
Do not write the test set from memory.
Use real support demand:
- Pull 100 recent conversations, tickets, chats, emails, contact-form submissions, or sales-support handoffs.
- Remove personal data and account identifiers.
- Group questions by intent, not wording.
- Mark each intent as answer, draft, handoff, or do-not-answer.
- Attach a source to every answer-lane and draft-lane intent.
- Keep a few known source gaps in the test set to verify that the agent can stop.
Zendesk’s automation potential report is a useful signal here. Zendesk says the report analyzes customer conversations to identify topics that are good candidates for AI automation, and where knowledge gaps exist. Zendesk Help
You do not need Zendesk to use the method. The durable idea is simple: let recent customer language decide what the POC tests.
Use a balanced set:
- 40 common questions the agent should answer
- 20 multi-turn questions where the customer changes, clarifies, or adds context
- 15 rephrased questions that ask the same thing in different ways
- 10 edge cases that should trigger draft or handoff
- 10 missing-source questions that should produce refusal or handoff
- 5 adversarial or risky questions that test policy boundaries
That gives you 100 test items. It is enough to reveal patterns without turning the POC into a six-month research project.
Score accuracy, citations, handoff, tone, and iteration
A POC should produce a scorecard your team can review.
Keep it short enough to use on every test case:
| Criterion | Pass means | Fail means |
|---|---|---|
| Accuracy | The answer matches the source and resolves the question. | The answer is wrong, incomplete, or too broad. |
| Citation quality | The answer cites the right source or explains why no source exists. | The answer has no source, the wrong source, or a vague citation. |
| Handoff quality | The agent stops early and passes context when needed. | The agent guesses, loops, or hands off with no useful summary. |
| Tone and control | The answer is clear, direct, and appropriate for the customer’s mood. | The answer sounds generic, overconfident, evasive, or too sales-heavy. |
| Improvement path | The failure points to a fix: source, instruction, scope, or process. | The team cannot tell why the agent failed or how to improve it. |
Use a 1-5 score for each criterion, but require hard gates for risky behavior.
Hard fails should include:
- unsupported policy claims
- made-up prices, timelines, or eligibility rules
- wrong refund, legal, medical, safety, or security advice
- exposing internal notes to a customer-facing answer
- refusing to hand off when the customer asks for a person
- giving a confident answer without a source for a source-required topic
Chatbase’s accuracy guide makes a related point: a fast wrong answer creates more work because a human has to step in and correct it. It recommends measuring failure rate, AI-handled CSAT separately from human-handled CSAT, and human agent feedback on escalation quality. Chatbase
That is the right mindset. The POC is not passed by high containment alone. It is passed by trusted resolution.
Test the failure modes first
Most teams test the happy path too early.
Start with the cases that can hurt trust:
Missing source
Ask a question the source set does not answer.
Pass:
I do not have a current source for that answer. I can pass this to the support team with the question and the sources I checked.
Fail:
Based on our usual policy, you should be eligible.
If the source is missing, “usual” is guessing.
Conflicting source
Put an old policy and a new policy in scope, then ask about the changed rule.
Pass:
I found conflicting information about this policy and should not answer it directly. I am sending this to the team.
Fail:
The old policy says X.
Conflicting sources are not a model creativity problem. They are a knowledge ownership problem.
Emotional customer
Ask the same factual question in an angry way.
Pass:
- acknowledges the problem briefly
- avoids arguing
- answers from source if safe
- offers handoff if the customer wants a person or the issue is sensitive
Fail:
- over-apologizes without resolving
- becomes defensive
- keeps asking the customer to rephrase
- ignores the request for a human
CX Dive’s May 2026 coverage of Chime’s AI agent Jade is useful here. Chime’s COO said the company would not block customers who wanted a human, and that its “hero metrics” were customer satisfaction and automated resolution rate together. CX Dive reported that Chime said automation handles 70% of interactions and that resolution rates increased by more than 40 percentage points. CX Dive
The lesson is not “copy Chime.” The lesson is that automation and customer trust need to be measured together.
Multi-source question
Ask a question that needs two sources.
Example:
I am on Starter and want to upload a scanned PDF. Will it count against my knowledge-base limit, and can the bot cite it?
Pass:
- answers from the plan docs and file-ingestion docs
- notes the processed-text cap if that is how the product works
- cites both sources
Fail:
- answers only the first part
- invents a limit
- cites a generic docs page that does not prove the answer
This test catches agents that look strong on single-article questions but fail when customers ask the way humans actually ask.
Run the POC as a two-week pilot
A one-hour vendor call is not a POC.
Use a short pilot:
Day 1: Scope
Pick one channel and one support area.
Good examples:
- website support widget for product and pricing FAQs
- help-center bot for setup questions
- internal support assistant for operator drafts
- Slack support triage for repeated internal questions
Avoid starting with every channel, every policy, every customer segment, and every action.
Days 2-3: Source cleanup
Fix the content before testing the agent.
Remove stale docs, split long policy pages, add missing direct answers, and separate internal-only material from customer-facing sources.
Days 4-6: Test set and baseline
Run the 100-item test set manually.
Record:
- score by criterion
- source cited
- expected lane
- actual lane
- failure reason
- fix owner
Days 7-9: Fix sources and rules
Do not jump straight to prompt changes.
Fix in this order:
- missing or stale source
- source wording or heading
- folder scope
- handoff rule
- answer instruction
Prompt edits are useful, but they should not compensate for bad source material.
Days 10-12: Re-test
Run the same test set plus 20 new questions.
The same test set tells you whether fixes worked. New questions tell you whether the agent learned the pattern or only passed the rehearsed examples.
Days 13-14: Decide launch scope
Do not make a binary “buy or do not buy” decision only.
Decide:
- which lane is production-ready
- which source gaps block launch
- which questions require human review
- which pages or channels should see the agent first
- what will be reviewed daily after launch
- who owns source fixes
The practical outcome of a POC might be: “Launch answer-lane support on docs and pricing pages, keep billing exceptions in handoff, and review citations daily for two weeks.”
That is a useful decision.
Do not use deflection as the only pass/fail metric
Deflection is easy to count and easy to abuse.
If the agent gives a wrong answer and the customer gives up, that can look like deflection. If the customer opens a second ticket later, the first dashboard may still look good.
Use better POC metrics:
- Answer accuracy. Did the answer match the source?
- Citation precision. Did the citation prove the answer?
- Handoff timing. Did the agent stop before trust was damaged?
- Recontact risk. Would the customer need to ask again?
- Source gap rate. How many failures were missing-documentation problems?
- Human cleanup time. Did drafts save time or create editing work?
- Customer effort. Did the customer avoid repeating the issue?
- Review speed. How quickly can the team diagnose and fix a failed answer?
CX Dive reported in May 2026 that 85% of service and support leaders are expanding human agent responsibilities as AI enters contact centers, while many are redesigning work rather than simply removing people. CX Dive
That is relevant to the POC. The question is not only “Can the AI close tickets?” It is “What does the human team do better because AI is handling the right work?”
Responsible AI belongs in the POC
Responsible AI should not be bolted on after launch.
The Australian Government’s National AI Centre reported in May 2026 that about 65% of non-adopting Australian SMEs cited distrust in AI decision-making or a preference for human control, and 19% said they did not know how to use AI in their business. It also noted that customer-facing governance practices, such as transparency and concern-raising processes, lag behind internal output checking. AI.gov.au
For a customer service AI POC, responsible AI is practical:
- tell customers when they are interacting with AI where appropriate
- require sources for policy, pricing, setup, and troubleshooting answers
- define topics the agent must not answer alone
- preserve a human path
- avoid exposing internal notes in customer replies
- review failed answers before expanding scope
- give operators a way to report knowledge gaps
You do not need a 40-page AI policy before testing a website support bot.
You do need control points that keep unsupported answers out of customer conversations.
Where Owlish fits
Owlish is a good fit when the POC is about grounded customer support, not generic chat.
Current Owlish workflows support:
- Website ingestion. Crawl public help centers, docs, and website pages, with allow and exclude patterns. Website source docs
- File ingestion. Upload PDFs, DOCX, CSV, TXT, Markdown, and static HTML. Scanned PDFs can use OCR fallback. File source docs
- Direct Response entries. Add short canonical answers for repeated questions or policy nuances that do not live in a full article yet. Direct Response docs
- Source citations. Inspect which source grounded an answer and fix the source when the answer is wrong. Citations docs
- Web widget deployment. Put the agent on your website and configure allowed domains and citation display. Web widget docs
- Human handoff. Let the visitor ask for a person, let the agent decide to hand off, or let an operator pull a conversation into the inbox. Human handoff docs
- Team-chat channels. Use Slack, Microsoft Teams, and Google Chat on Growth and above when the same agent should support internal or team-chat workflows. Plans docs
Use Owlish in a POC when you want to test whether a support agent can answer from your website, documents, PDFs, and FAQ entries with citations and a clean path to a human.
Do not use Owlish as the first choice if your POC depends on deep telephony, workforce management, native Shopify order actions, or a full Zendesk or Salesforce migration on day one. In those cases, test a helpdesk suite or a custom integration first, then bring a grounded website or knowledge-base agent into the support mix when the source and handoff model are clear.
AI customer service agent POC checklist
Use this checklist before calling a POC successful:
- The test set uses real customer language, not vendor demo prompts.
- Every direct answer has a current source.
- The agent cites the source that actually proves the answer.
- Sensitive topics have stop rules.
- The customer can ask for a human.
- Handoff includes a useful summary and the reason the agent stopped.
- The agent handles rephrased, vague, and multi-turn questions.
- Missing-source questions produce refusal or handoff, not guesses.
- Human reviewers can label failures by source, scope, instruction, or handoff rule.
- The team knows what will be reviewed daily after launch.
If the POC passes only when the questions are clean, the POC did not test customer support. It tested a demo.
FAQ
What is an AI customer service agent POC?
An AI customer service agent POC is a short proof of concept that tests whether an AI agent can handle real support questions under realistic conditions. A useful POC checks answer accuracy, source citations, human handoff, tone, failure behavior, and how quickly the team can improve the agent after launch.
How long should an AI support agent POC take?
Most small teams can run a useful POC in about two weeks if the scope is narrow. The first week should focus on source cleanup, real-question test sets, and baseline scoring. The second week should fix sources and rules, re-test, and decide a limited launch scope.
What metrics should I use in an AI customer support POC?
Use answer accuracy, citation quality, handoff timing, recontact risk, source gap rate, human cleanup time, customer effort, and review speed. Do not rely on deflection alone because a bad answer can look like a closed conversation until the customer comes back later.
Should the POC include human handoff?
Yes. Human handoff is not an optional edge case. A customer-facing AI agent needs to know when to stop, how to explain the stop, and what context to pass to the person taking over.
What questions should I include in the test set?
Include common questions, multi-turn questions, rephrased questions, edge cases, missing-source questions, and risky questions that should trigger refusal or handoff. Use recent support conversations as the source, then remove personal data before testing.
Sources and further reading
- Intercom: What really matters when evaluating AI Agents for customer service
- Zendesk Help: Automation potential report
- CX Dive: How Chime overcame trust challenges when deploying its AI agent
- CX Dive: Contact centers pursue workforce redesign over mass layoffs
- AI.gov.au: AI adoption insights, December 2025 to February 2026
- Slack: Introducing new AI steps in Workflow Builder
- Chatbase: How to improve AI chatbot accuracy
If your first POC should test grounded answers, citations, and human handoff instead of a generic chatbot demo, build an Owlish agent from your website and support docs, then run the checklist above before sending real traffic to it.